

I travelled to Paris over the last week for the Reproducible Builds workshop there, as well as a GNU Guix meetup on the day before. All in all, it's been awesome, if a little tiring.
It was reassuring to spend some time with others who care enough about free software and related things to take a number of days out to come together and work on reproducible builds and related topics.


Monday, Guix meeting at Inria

I'm very thankful to Ludovic and Inria to organising and hosting the event.
I've been looking at code review and automated testing in the last few weeks, and I think the discussions around that did move things forward.
The issue of substitute delivery for GNU Guix was also discussed a few times, and at the Reproducible Builds summit, the presence of some people who were very knowledgeable about IPFS (the Inter Planetary File System) at the summit were very helpful.
Tuesday, Start of the Reproducible Builds workshop
The morning was filled with some knowledge sharing sessions, which was great for me, as this was my first reproducible builds summit.
I know now a little more about the Reproducible Builds organisations infrastructure, and I discussed the technical side of getting data regarding the reproducible of Guix packages in to the Reproducible Builds database.
The agenda and notes for the event are available here.


Wednesday
In the morning, I talked to others in the cross distribution session on Guix things, issues with upstreams and various other topics.
I was already thinking about a patch I made to Ruby, and used in govuk-guix to make downloading Rubygems more reproducible, however I was hesitant to push it upstream as I wasn't sure it was more generally useful. I ended up talking about this in the skill share session, and found someone else who was interested in Ruby reproducible builds. I've now pushed that patch up for review.


Thursday
I went along to a session on rebuilders, mostly to try and figure out
the relevance to Guix. I have a better understanding of this
now. Guix, and some other projects (Nix, maybe F-Droid, ...) already
have some of the pieces of this just due to how they normally
work. For Guix, the technical side of a "rebuilder" is just a standard
"build farm", ci.guix.info, or hydra.gnu.org for example.
The client verification with rebuilders is also mostly in place already for Guix. Whereas in Debian, you need to use the buildinfo files to check with rebuilders about the results they got, the narinfo files Guix uses when trying to find substitutes already fulfil this purpose, just because of how Guix works.

I'm looking forward to all of the things that these events have boosted. The next month or two is going to be very interesting, with things like FOSDEM coming up at the start of February, and Guix maybe releasing a 1.0 around then.

Freenode #live happened again, and like last year, it was in Bristol over the weekend.
Unlike last year, I'm not doing a talk, but this year I did head out to Bristol on the Thursday to allow some time before the conference begun on Saturday to do some exploring.
On the Thursday
Walking up to the Clifton Suspension Bridge was great. I crossed to the west of the river, walked up to the bridge and then over.
 |
 |
 |
 |

On the way back, I visited the Calbot Tower. The light was fading by this point, which was great to see looking down on Bristol.



On the Friday
I set off to visit two places. First the SS Great Britain, then the Bristol Museum & Art Gallery.
The SS Great Britain was well worth a visit. I'd somehow managed to miss this when walking along the opposite short of the river only the day before.



I visited the Calbot tower again, this time in the light.
Still the same amazing view, just now I could see a bit more in the daylight.


I was impressed by the amount of stuff in the museum.
It just kept going on and on. The range was impressive as well, like a mini British Museum. It had exhibits on sea life along the coast, ancient Egypt and Assyria, maps of Bristol, dinosaurs, minerals, glassware and a whole range of other art.
On the Saturday
Saturday was the actual first day of the conference. Chris Lamb's talk| was a nice way to start.
The schedule is available online, and talk videos are available on YouTube it's well worth talking a look at what videos are available. I've directly linked to those I comment on below.
Doc Searls and Simon Phipps - In Conversation
I didn't know anything about either speakers prior to the conference, and I still don't know that much, but they both had really interesting things to say and interesting perspectives.
Doc Searls opened with some great comments on privacy, this then led on to discussion of the GDPR.
"The because effect" (10:08) was interesting with respect to the money aspect of free software.
Some very insightful comments were made with respect to cloud computing. Copyleft came up (16:57).
Something which resonated with me quite a bit was the reiteration of the "open source is simply a marketing term for free software" (23:13).
John Sullivan - How can free communication tools win?
Communication tools are a important intersection where both software freedom and interoperability/federation really matter, and this talk was great at presenting the problems faced.
Bradley Kuhn - Interactive chat and the future of software freedom
I think this was my favourite talk of the conference, it's really worth a watch.
On the Sunday
GNU Emacs for all
An excellent talk, reminded me that while I've come a long way with Emacs, there's still a lot more to take advantage of.
Kyle Rankin - The death and resurrection of Linux Journal
A trip back through time, in the context of the Linux Journal.
Neil McGovern - Software desktops to 2025 and beyond!
A look at desktops, with some interesting perspectives from Neil, the current executive director of the GNOME Foundation.
VM Brasseur - Four ways to spread the four freedoms
I really liked the start of this talk, beginning with the 4 freedoms. However, some of the points made later felt particularly polarising.
Particularly at one point with regard to operating systems, the speaker makes the point that free software should be provided and supported on Microsoft Windows, but there isn't any suggestion of how to practically do this.
My guess is that there's a lot of dependency issues with even getting some software to work on Windows, let alone attempting to provide support for something that the contributors might not even have used.
Finally...
All in all, it was a great conference. I'm very grateful to all the organisers and speakers.
The single track this year meant I actually saw most of the talks. I didn't speak, but I did enjoy the time that gave me to explore Bristol a bit, and actually enjoy the conference a bit more.
I did take a few more photos, which are available in this album.
Hopefully there will be another Freenode #live next year!

I ordered a Librem 13, all the way back at the end of June (2017), and it was shipped at the end of October.
Prior to getting my Librem 13, I've been using a Lenovo T431s which is a great little laptop. The hardware worked ok with Debian, although the Intel Wi-Fi card required some non-free software (iwlwifi), and I never tried the fingerprint reader. The hardware is also a little limiting, as there isn't any support for M.2 SSDs, and it can only support 12GB of RAM.
The Librem 13 however supports up to 16GB of RAM, as well as a M.2 SSD. Rather than using Debian, I've been transitioning to use GNU Guix for a couple of years now, so this is what I installed on my new Librem 13, hence the stickers I added!
I brought the laptop with a M.2 SSD in it, but then put a SATA SSD in as well. This required a bit of fiddling as one of the internal cables was in the space for the SSD, so I had to move it a bit.

I was planning to put the Guix store on the bigger SATA SSD, while keeping the root partition on the M.2 SSD, with both disks using Btrfs on top of dm-crypt.
Unfortunately I had some issues setting this up. The partitioning scheme I had in mind isn't quite supported by GuixSD yet, as if I remember correctly, the Grub configuration generated is incorrect. For now, I just have the store on the M.2 SSD.

As for using it, the main issue I've had is the webcam initially not working, which is a bit of a non-issue, as I don't have much use for the webcam. I've been in contact with Purism support, and I could return it for a replacement, but at the moment I'm fine with the one I've got. However, today the webcam sprang in to life for a few minutes, which is pretty exciting.
The other minor gripe I have is not being able to tell if it's off or suspended without opening it up. The T431s has a little red LED on the top, which will pulsate if it's suspended, which is reassuring that it's actually suspended when you close the lid.
As for the rest of the hardware, it's pretty awesome. The case feels very tough and sturdy, and the keyboard and trackpad work well. All in all, I think it's a great bit of hardware, and I really like Purism's emphasis on user freedoms through free software.

I've been using Bytemark for a while now, both personally and professionally, and one thing that has got me excited recently is running GuixSD on Bytemark VMs.
A while back, I installed GuixSD on a Bytemark VM first by creating a VM on Bytemark using Debian as the operating system, then installing Guix within Debian, then using that installation of Guix to install GuixSD over the top of Debian.

This "over the top" approach works surprisingly well, you just have to remove a few key files from Debian before rebooting, to ensure GuixSD is able to boot. It does have several disadvantages though, its quite slow to install GuixSD this way, and you have to manually clean out the Debian related files.
Bytemark do support inserting ISO images in to the VMs, which can be used to install operating systems. Up until recently, Guix didn't have an ISO installer, but now, with the 0.14.0 release, there is one available.
In case you're interested, here is a quick description of what this involves. You might want to follow along with the full system installation documentation at the same time.
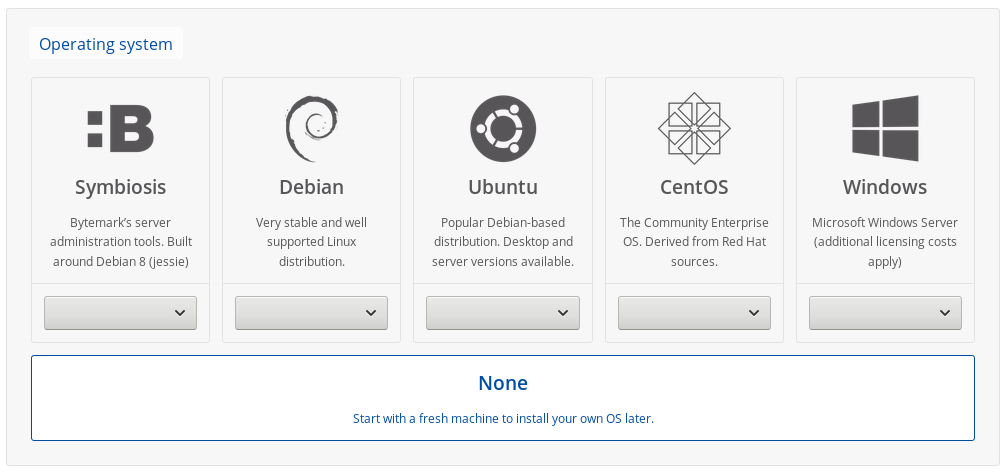
Step 1: Create a new cloud server
I selected mostly the defaults: 1 core, 1 GiB of RAM, 25 GiB of SSD storage. For installing GuixSD, select None for the operating system.
Step 2: Insert the GuixSD installer ISO
Open up the server details, and click the yellow "Insert CD" button on the left.
Pop in a URL for the installation image. It needs to be decompressed, unlike the image you can download from the Guix website.
To make this easier, I've provided a link to a decompressed image below. Obviously using this involves trusting me, so you might want to decompress the image yourself and upload it somewhere.
https://www.cbaines.net/posts/bytemark_server_with_guixsd/guixsd-install-0.14.0.x86_64-linux.iso
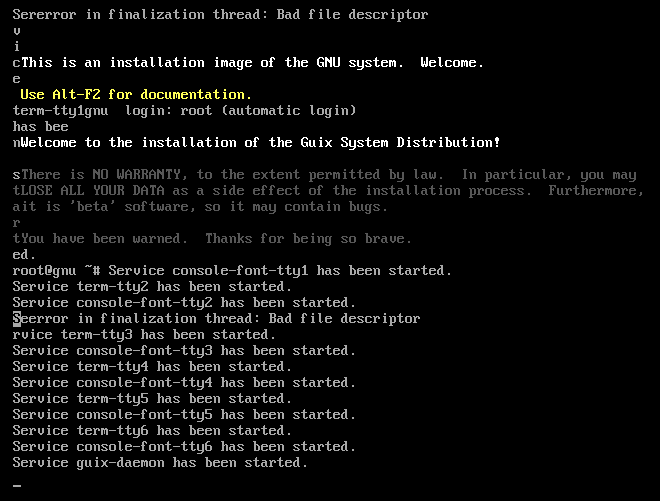
Step 3: Boot in to the installer
After that is done, click the VNC button for the server to the top right, and once the window for that opens up, click the red "Ctrl + Alt + Delete" button to trigger the system to restart. This should get it to boot in to the installation image.
Step 4: Setup networking
Run the following commands to bring up the network interface, and get an IP address.
ifconfig eth0 up
dhclient eth0
Step 5: (Optional) Start the SSH daemon
If you're happy using the web based console, the you can continue doing that. However, the installer includes a ssh-daemon service which can be used to continue the installation process over SSH.
If you want to use this, use the passwd command to set a password for the root user, and then start the ssh-daemon service.
passwd
herd start ssh-daemon
After doing this, you can find out the IP address, either from the Bytemark panel, or by running:
ip addr
Once you have the IP address, login to the machine through SSH and continue with the installation process.
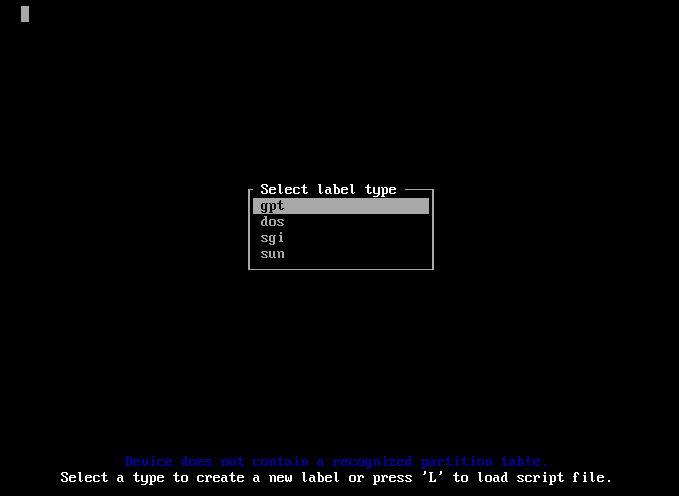
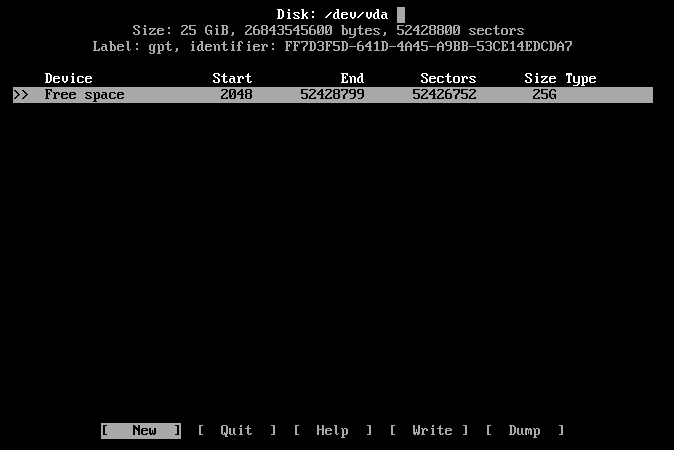
Step 6: Partition the disk
Select the default partitioning type, gpt.
Create a "2M" BIOS Boot partition, and then a 25GB Linux filesystem.
After that select the "[ Write ]" option, and then the "[ Quit ]" option.
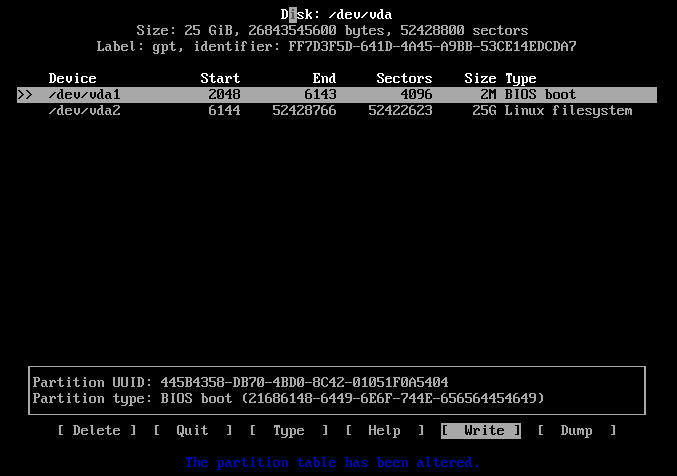
Step 7: Create and mount the root filesystem
mkfs.ext4 -L root /dev/vda1
mount LABEL=root /mnt
Step 8: Write the configuration
mkdir /mnt/etc
cp /etc/configuration/bare-bones.scm /mnt/etc/config.scm
I then edited this file with nano, mostly as using zile with C-n for move down kept opening new browser windows.
- Changed the hostname and timezone
- Set the bootloader target to "/dev/vda"
- Changed the filesystem device to root
- Set the name of the user
- Change the home directory
Step 9: Start the cow-store service
herd start cow-store /mnt
Step 10: Run guix system init
I did have some problems at this point, as the VM appeared to reboot. I tried again, but this time with the --no-grafts option, and it worked. If you encounter something similar, try adding the --no-grafts option to guix system init, and I'd also be interested to know.
guix system init /mnt/etc/config.scm /mnt
...
Installation finished. No error reported.
If this works succesfully, you should see the above message at the end.
Finish: Reboot in to GuixSD
Reboot, and then remove the CD from the system using the Bytemark panel.
reboot
If you run in to any trouble, there is a IRC channel (#guix on Freenode) and a mailing list where you can ask for help.
Also, while this guide may go out of date, if you do have any suggestions or corrections, you can email me about them.
The first Freenode #live conference happened on the weekend just passed (28th and 29th of October), and it was awesome but exhausting.
I met up with many people, some who I'd met at previous events like the recent GNU Hackers Meeting and others who I'd not met before.
The speaker events, both the cheese and open bar in a pub on the Friday, and the formal dinner on the Saturday were very enjoyable with lots of interesting conversation.
I gave a talk on Guix, (view the slides). As always, while I submitted the proposal a while in advance, I was editing the notes right up until Sunday morning.
The freenode staff did an awesome job organising the event, and what they pulled off was incredible given the ticket costs. I'm guessing this was due to the generous sponsorship.
All in all, I'm hoping to attend next year!
![]()
I'm off to Spain next week, for some sun, sightseeing and Debian, but before I left, I decided to attend the NHS Hack Day over this weekend (14th and 15th of May 2016).
The day started with presentations, and at first I was interested by many of them. The spreadsheet is still online, but I put the following projects on my shortlist:
- Better blood results
- British english medical spelling dictionary
- CAMHS Inpatient Bed Finder
- Daily pollute
- Rota Manager
- Dockerised integration engine
After doing some walking and talking to different people in the room, I ended up sitting with Mike and Tony who work in the NHS at King's College Hospital as developers and were behind the "Dockerised intergration engine" project, and Piete who has some experience with system architecture and Docker in particular.
After a bit of discussion, it turned out that the main problems that Mike and Tony had, was that they were using tools, both for a framework, and deployment processes that they did not have much experience with, and this manifested in having one large "monolith", which required restarting when changes to any component were required.
At this point, I left Piete, Mike and Tony to work on just setting up a smaller isolated service, using Docker and NodeJS, which Tony already knew a bit about, but was interested in getting more experience in.
Now it was lunchtime, and I ended up sitting with Calum (who I have met before at Many to Many) and Devon, who had proposed the "British English medical spelling dictionary" project earlier in the morning.
We decided to have a go at this project, and set about working out the goals, and what work would be required to achieve them. I ended up doing some research in to generating a wordlist (which we ended up not doing), the initial tweaks to the website style, and attempting to create a extension for LibreOffice which would install a dictionary (which was not finished).
The website and corresponding Git repository for the website and project can give a detailed information about the actual work that was done.
As is the case sometimes with these events, the real value is found in the conversations had both on the topic, as was the case when I was discussing the problems that Mike and Tony face day to day, and the discussions I had with Devon, Calum and others, both at the even, and on Saturday evening in the pub on diverse topics of software (including free software, Guix and Debian) and Matt about some of his work and background.
All in all, I'm glad I took the time to attend.
Prometheus (website) has been used on and off by Thread since May 2015 (before I joined in June). Its a free software time series database which is very useful for monitoring systems and services.
There was a brief gap in use, but then I set it up again in October, driven by the need to monitor machine resources, and monitor the length of the queues (Thread use django lightweight queue). This proved very useful, as suddenly when a problem arose, you could look at the queues and machine stats which helped greatly in determining the correct course of action.
When using Prometheus, the server scrapes metrics from services that expose them (e.g. the prometheus-node-exporter). This is a common pattern, and I had already thrown together a exporter for django lightweight queue (that just simply got the data out of redis), so as new and interesting problems occured, I began looking at how Prometheus could be used to provide better visiblity.
PGBouncer
The first issue that I addressed was a fun issue with exausting the pgbouncer connection pool. The first time this happened, it was only noticed as emails were being sent really slowly, and eventually it was determined that this was due to workers waiting for a database connection. PGBouncer does expose metrics, but having them in Prometheus makes them accessible, so I wrote a Prometheus exporter for PGBouncer.
The data from this is displayed on relevant dashboards in Grafana, and has helped more than once to quickly solve issues. Recently, the prometheus-pgbouncer-exporter was accepted in to Debian, which will hopefully make it easy for others to install and use.
HAProxy logs
With the success of the PGBouncer exporter, I recently started working on another exporter, this time for HAProxy. Now, there is already a HAProxy exporter, but the metrics which I wanted (per HTTP request path rates, per HTTP request path response duration histograms, ...) are not something that it offers (as it just exposes metrics on the status page). These are something that you can get from the HAProxy logs, and there are existing libraries to parse this, which made it easier to put together an exporter.
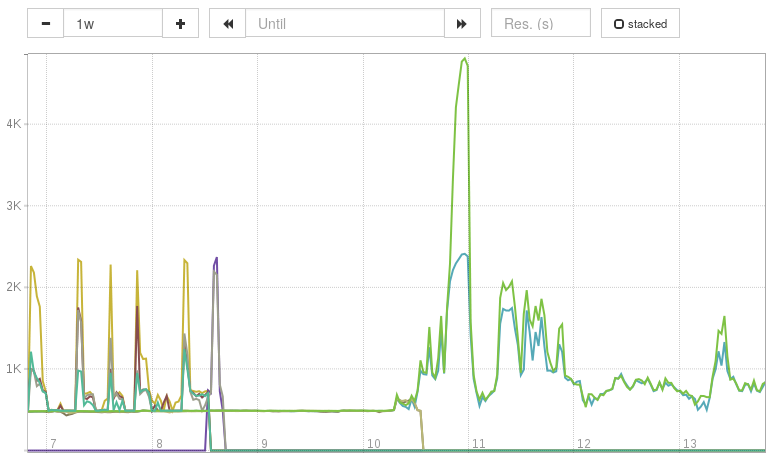
It was using the data from the HAProxy log exporter that I began to get a better grasp on the power of aggregating metrics. The HAProxy log exporter, exports a metric haproxy_log_requests_total and this can have a number of labels (status_code, frontend_name, backend_name, server_name, http_request_path, http_request_method, client_ip, client_port). Say you enable the status_code, server_name and http_request_method labels, then, if you want to get a rate of requests per status code (e.g. to check the rate of HTTP 500 responses), you just run:
sum(rate(haproxy_log_requests_total[1m])) by (status_code)
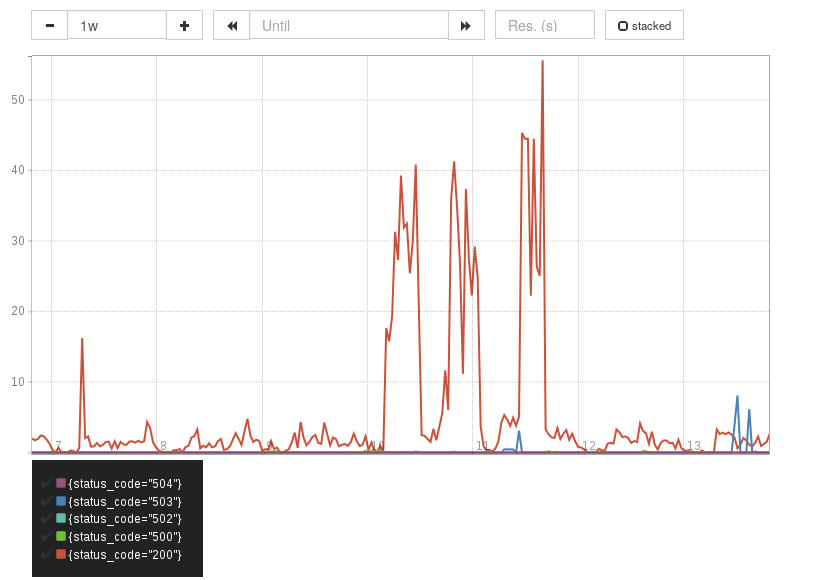 Per second request rates, split by status code (key shown at the bottom).
Per second request rates, split by status code (key shown at the bottom).
Perhaps you want to compare the performance of two servers for the different request paths, you would run:
sum(
rate(haproxy_log_requests_total[1m])
) by (
http_request_path, server_name
)
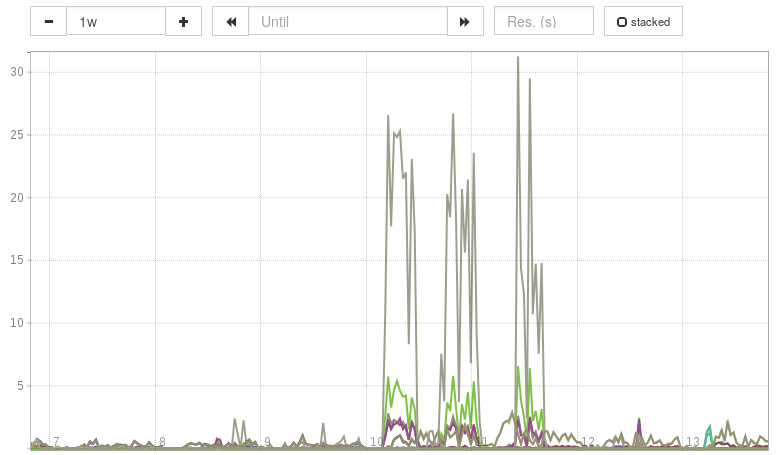 Each metric represents the request rate for a single request path (e.g. /foo)
for a single server.
Each metric represents the request rate for a single request path (e.g. /foo)
for a single server.
And everything you can do with a simple counter, you can also do with histograms for response duration. So say you want to know how a particular request path is being handled over a set of servers, you can run:
histogram_quantile(
0.95,
sum(
rate(haproxy_log_response_processing_milliseconds_bucket[20m])
) by (
http_request_path, le, server_name
)
)
 Each metric represents the 95 percentile request rate for a single request
path, for a single server.
Each metric represents the 95 percentile request rate for a single request
path, for a single server.
This last query is aggregating the culamative histograms exported for each set of label values, allowing very flexible views on the response processing duration.
Next steps
At the moment, both exporters are running fine. The PGBouncer exporter is in Debian, and I am planning to do the same with the HAProxy log exporter (however, this will take a little longer as there are missing dependencies).
The next things I am interested in exploring in Prometheus is its capability to make metrics avaialble for automated alerting.
On Monday I started working on Thread. A 3 year old startup that has set out to reinvent how the world buys clothes.
On arrival, I began setting my office machine up with Debian, and left it cloning the rather large git repository while I and the rest of the company went out to a nearby pub for lunch. By the end of the day I had my office machine setup, my name on the website and had begun working on a small feature for the order management part of the site.
On Tuesday, work came to a halt at 11:30. Everyone set of to London Fields for the picnic in celebration of Thread's 3rd birthday.
Wednesday was actually normal as far as I can remember, Thursday featured a office movie night, and today (Friday) I had published my first contribution to the site, along with enjoying my first office lunch.
Thread use a great set of technologies, Python, Django, PostgreSQL and Debian. I have learned loads in just my first week, and I can't wait to get stuck in over the next few weeks.

My last event in Southampton last week was the Maptime Southampton June meetup. This was a joint event organised by Charlie (who regularly organises Maptime Southampton) and Rebecca Kinge who I believe runs Dangerous Ideas Southampton.
The event, Mapping Real Treasure featured some introductions from Charlie and Rebecca, and then several small talks from various interesting people, and myself.
Other talks included a map of fruit trees, Placebook, some work by the University of Southampton and SUSU relating to students and local businesses from Julia Kendal, Chris Gutteridge's recent Minecraft/OpenStreetMap/Open Data project, and some very cool OpenStreetMap jigsaw pieces from Rebecca's husband (whose name I cannot remember/find).
The slides (git repository) for my talk are available. The aim was to give a brief introduction to what OpenStreetMap is, particularly mentioning interesting things like the Humanitarian OpenStreetMap Team.
I was not quite expecting to be presenting to such a large (~50 people!) varied audience (age and gender). In hindsight, I should have probably done a better sell of OSM, rather than the talk I gave, which was more technical in nature. I ended up talking more on the nature of OSM being a digital map, consisting of data, and skipping over the slides I had on editing OSM, I did however demo using iD at the end of the presentation (although I should have perhaps had this as a bigger part).
Towards the end of the presentation, I discussed the legal side of OSM, in terms of the copyright of the data, and the licensing. Although, again I am unsure if I approached this issue correctly, I think I should have probably given examples of what you can do with OSM, and then related this back to the license and copyright.
I should probably also mention the Maptime May meetup, where I ran a smaller workshop on OpenStreetMap and the Humanitarian OpenStreetMap Team. For this I wrote two presentations, one for OSM and the other specifically for HOT. The shorter presentation I gave recently was adapted from these two presentations.
Take any software project, on its own its probably not very useful. First of all, you probably need a complier or interpreter, something to directly run the software, or convert the source form (preferred form for editing), to a form which can be run by the computer.
In addition to this compiler or interpreter, it's very unusual to have software which does not use other software projects. This might require the availability of these other projects when compiling, or just at runtime.
So say you write some software, the other bits of software that your users must have to build it (generate the useful form of the software, from the source form) are called build dependencies. Any bits of software that are required when your software is run are called runtime dependencies.
This complexity can make trying to use software a bit difficult... You find some software on the web, it sounds good, so you download it. First of all, you need to satisfy all the build dependencies, and their dependencies, and so on... If you manage to make it this far, you can then actually compile/run the software. After this, you then need to install all the runtime dependencies, and their dependencies, and so on... before you can run the software.
This is a rather offputting situation. Making modular software is good practice, but even adding one direct dependency can add many more indirect dependencies.
Now there are systems to help with this, but unfortunately I don't think there is yet a perfect, or even good approach. The above description may make this seem easy to manage, but many of the systems around fall short.
Software Packages
Software packages, or just packages for short is a term describing some software (normally a single software project), in some form (source, binary, or perhaps both), along with some metadata (information about the software, e.g. version or contributors).
Packages are the key component of the (poor) solutions discussed below to the problem of distributing, and using software.
Debian Packages
Debian, "The universal operating system" uses packages (*.deb's). Debian packages are written as source packages, that can be built to create binary packages (one source package can make many binary packages). Debian packages are primarily distributed as binary packages (which means that the user does not have to install the build dependencies, or spend time building the package).
Packaging the operating system from the bottom up has its advantages. This means that Debian can attempt to solve complex issues like bootstrapping (building all packages from scratch), reproducible builds (making sure the build process works exactly the same when the time, system name, or other irrelevant things are different).
Using Debian's packages does have some disadvantages. They only work if you are installing the package into the operating system. This is quite a big deal, especially if you are not the owner of the system which you are using. You can also only install one version of a Debian package on your system. This means that for some software projects, there are different packages for different versions (normally different major versions) of the software.
npm Packages
On the other end of the spectrum, you have package managers like npm. This is a language specific package manager for the JavaScript language. It allows any user to install packages, and you can install one package several times on your system.
However, npm has no concept of source packages, which means its difficult to ensure that the software you are using is secure, and that it does what it says it will. It is also of limited scope (although this is not necessarily bad).
Something better...
I feel that there must be some middle ground between these two situations. Maybe involving, one, two, or more separate or interconnected bits of software that together can provide all the desirable properties.
I think that language specific package managers are only currently good for development, when it comes to deployment, you often need something that can manage more of the system.
Also, language specific package managers do not account for dependencies that cross language boundaries. This means that you cannot really reason about reproducible builds, or bootstrapping with a language specific package manager.
On the other end of the scale, Debian binary packages are effectively just archives that you unpack in to the root directory. They assume absolute and relative paths, which makes them unsuitable for installing elsewhere (e.g. in a users home directory). This means that it is not possible to use them if you do not have root access on the system.
All is not yet lost...
There are some signs of light in the darkness. Debian's reproducible builds initiative is progressing well. In the Debian way, this has ramifications for everyone, as an effort will be made to include any changes made in Debian, in the software projects themselves.
I am also hearing more and more about package managers that seem to be in roughly the right spot. Nix and Guix, although I have used neither both sound enticing, promising "atomic upgrades and rollbacks, side-by-side installation of multiple versions of a package, multi-user package management and easy setup of build environments" (from the Nix homepage). Although with great power comes great responsibility, performing security updates in Debian would probably be more complex if there could be multiple installations, of perhaps versions of an insecure piece of software on a system.
Perhaps some semantic web technologies can play a part. URI's could prove useful as unique identifiers for software, and software versions. Basic package descriptions could be written in RDF, using URI's, allowing these to be used by multiple packaging systems (the ability to have sameAs properties in RDF might be useful).
At the moment, I am working on Debian packages. I depend on these for most of my computers. Unfortunately, for some of the software projects I write, it is not really possible to just depend on Debian packages. For some I have managed to get by with git submodules, for others I have entered the insane world of shell scripts which just download the dependencies off the web, sometimes also using Bower and Grunt.
Needless to say I am always on the look out for ways to improve this situation.